
Earlier this year, the NCSC published new guidance on ‘Using cloud services securely’. Today we are adding a section on How to ‘lift and shift’ successfully to this collection.
‘Lift and shift’ is the practice of replicating an existing local system, machine-for-machine, but in the cloud. You might be wondering ‘Doesn’t lift and shift result in one of the NCSC’s 6 Security architecture anti patterns?’ And you’d be right (it’s number 4).
However, the NCSC also recognise that:
- it is one of the most commonly used cloud migration paths
- there are a small handful of sensible use-cases where lift and shift is a good idea
Our aim with this guidance is to provide advice on how to avoid the biggest pitfalls of this anti pattern.
In this blog, I’ll explain some of the common pull factors of moving to the cloud (specifically security, scalability and resilience), and investigate how these might be affected by taking a basic lift and shift approach.
Security
A common pull factor when moving to the cloud is that the cloud provider will keep the platform up to date with the latest security patches and updates. This removes the burden of patching from your IT team, and passes responsibility to the cloud providers hardened infrastructure experts. And this is true, the provider will keep their infrastructure and software up to date and secured.
However, by performing a basic lift and shift migration, you will retain the highest level of management responsibility of your systems when compared to other migrations strategies. Lift and shift takes all the problems your engineering teams are experiencing on-prem, and moves them to the cloud.
For example:
- keeping on top of the latest security patches
- maintaining system availability
With this basic migration technique you will now have the additional overhead and risks associated with maintaining and securing a cloud platform, without taking advantage of the benefits it can offer you.
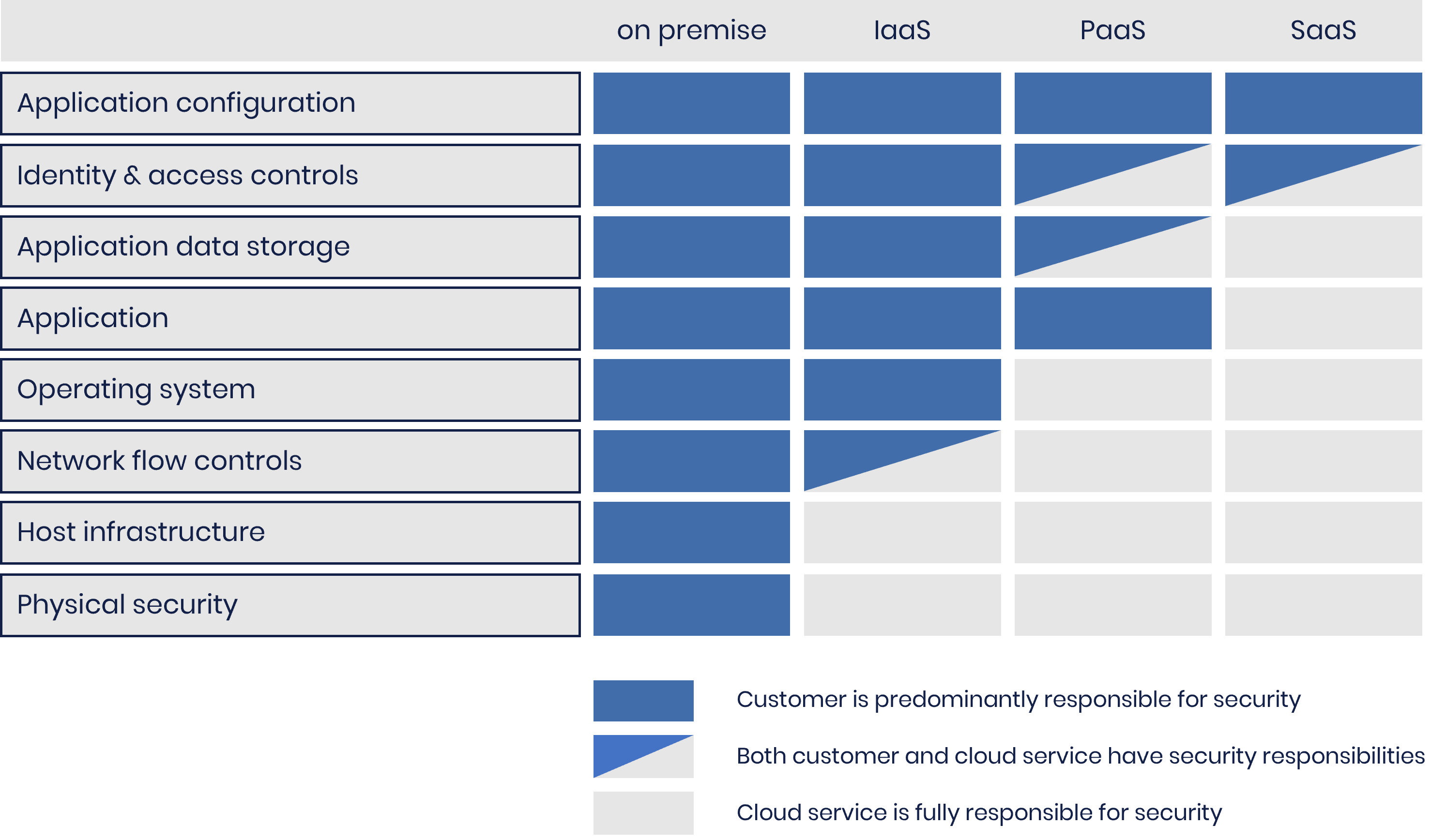
The cloud provider will maintain the hardware and virtualisation layers, but you will have to maintain everything running on top of that, from operating systems through to application software. The diagram below shows a comparison of the split of responsibility across the cloud service models.
This means you won’t fully gain the security benefits of shifting maintenance overhead to the cloud provider; only by moving beyond a basic lift and shift will these start to be realised. Our new guidance provides advice on how you can start to benefit from this migration pathway and begin leveraging the tools and services offered in the cloud. Extracts from the guidance include:
- Replace legacy management protocols with managed secure access mechanism
- Replace simple single use appliances with managed equivalents (e.g load balancers and firewalls)
- Use cloud services to automate the patching of your virtual machines
CLOUD SECURITY SHARED RESPONSIBILITY MODEL
Scalability
A popular pull factor of moving to the cloud is the offer of seemingly unlimited resources that will scale up and down depending on your systems load.
By performing a basic lift and shift migration, your applications won’t automatically gain the auto-scaling capabilities cloud services can offer. You will be able to manually deploy as many resources as you like, but to automate this to meet demand, you will need to architect your services to incorporate auto-scaling features provided by your cloud provider.
Resilience
The final pull factor I’m going to investigate is resilience. Moving to the cloud can offer improved availability of your systems with features like:
- automated failover if outages occur
- improved disaster recovery with cloud backups and the ability to quickly rebuild with infrastructure as code
- improved protection against DDoS attacks, with traffic absorbed through the huge networks that make up cloud platforms
By performing a basic lift and shift migration to the cloud, your system won’t automatically gain all the resilience benefits on offer. With automated failover for example, your services will need to be designed to use the availability features cloud providers offer. By designing your systems to have resources located in different availability zones, they will be able to failover to healthy virtual machines in the event of an outage. However, be aware that simply replicating your system across different zones has the potential to cause you more headaches than it solves. Your system needs to know how to handle multiple sets of resources properly to avoid ending up in an even more broken state than the one it was trying to solve.
Backups of your virtual servers also won’t be automatically taken when you move to the cloud. You will need to design your systems to use the backup features provided in the cloud.
As we’ve discussed, lift and shift is not a recommended practice. However, our new guidance explains how by going beyond a simple lift and shift implementation, you can avoid the worst problems of the migration strategy.
Source: https://www.ncsc.gov.uk/blog-post/new-cloud-guidance-lift-shift-successfully